Advantages:
- Reduces neuron count by 72% (breast cancer) and 36.8% (MNIST) for efficiency
- Maintains high accuracy with only 5.25% average loss for MNIST dataset pruning
- Optimized for IoT and edge computing by reducing computational and memory needs
- Uses mean-based pruning for tanh activation to enhance model performance efficiently
Summary:
Modern neural networks are increasingly complex, requiring significant computational power and memory. This presents a challenge for deploying AI on resource-constrained devices like IoT sensors, edge computing platforms, and embedded systems, where efficiency, speed, and power consumption are critical. Traditional optimization methods often struggle to balance performance with model size, leading to bottlenecks in real-world applications.
This technology introduces a novel pruning method for Multi-layer Perceptrons (MLPs) that efficiently removes redundant neurons while maintaining accuracy. By leveraging the tanh activation function, it reduces neuron counts by 36.8% for MNIST models and up to 72% for the breast cancer dataset, ensuring minimal accuracy loss. This approach optimizes neural networks for real-world deployment, making AI models faster, more efficient, and better suited for edge and IoT applications.
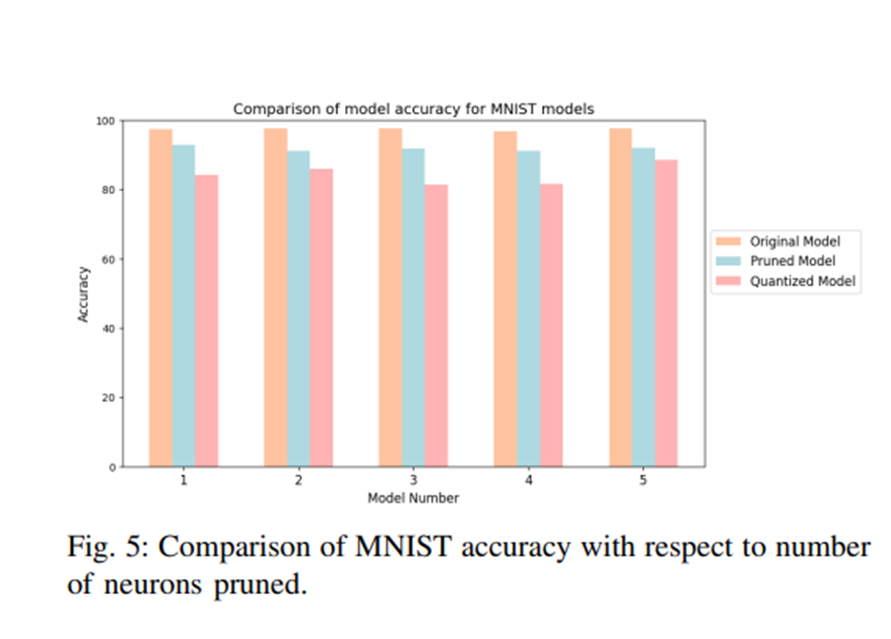
This chart demonstrates the impact of pruning on neural networks, showcasing accuracy levels for the original, pruned, and quantized models using the MNIST dataset. It highlights how pruning effectively reduces model complexity while maintaining high accuracy, making it suitable for resource-constrained applications like IoT and edge computing.
Desired Partnerships:
- License
- Sponsored Research
- Co-Development